▸ Tag · #vector-search
Posts tagged #vector-search.
2 posts with this tag.
-
 Architecture
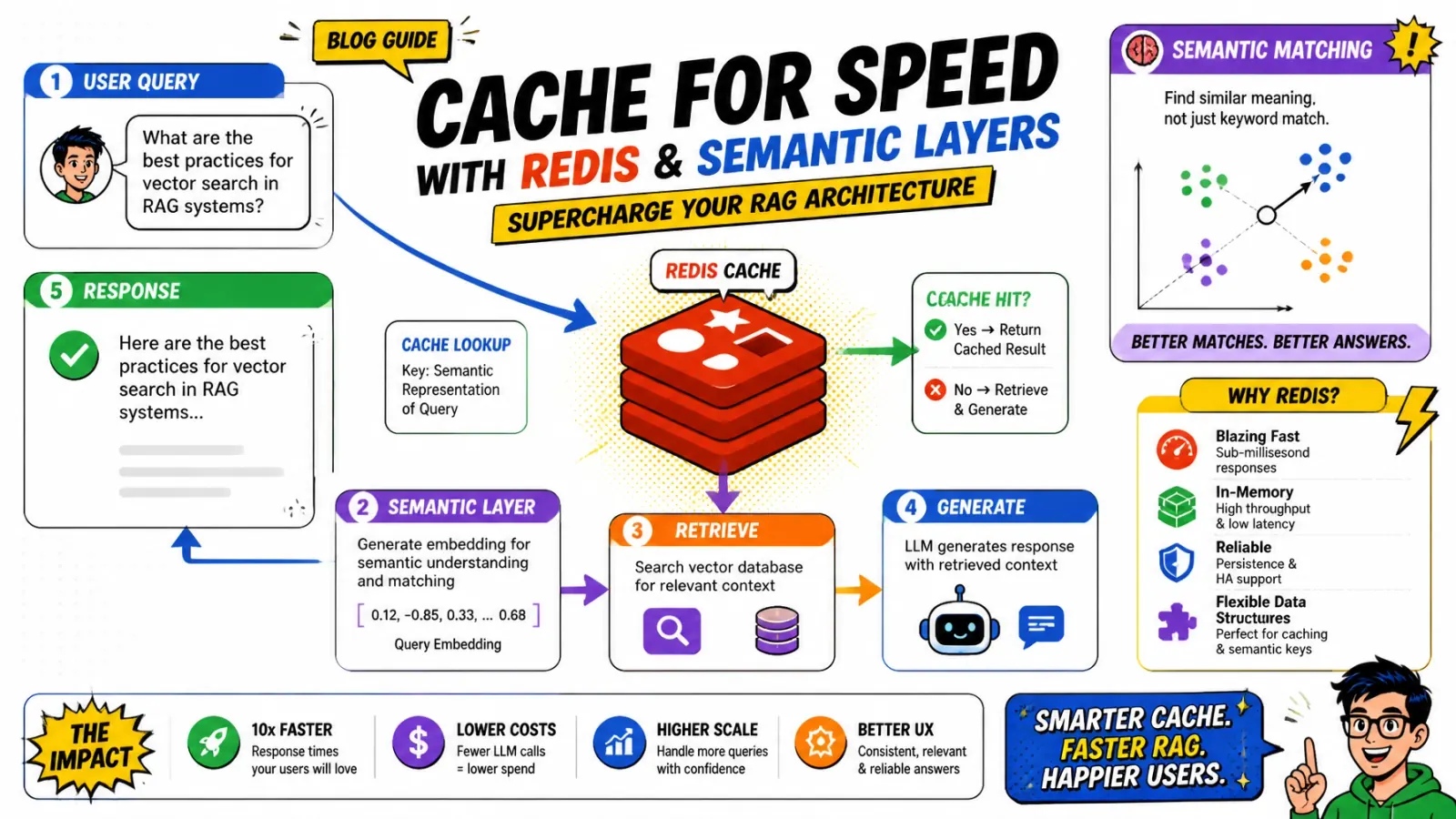
ArchitectureCaching for speed: Redis and semantic layers in RAG
Stop paying for the same LLM call twice. Two-tier caching — exact-match Redis keys plus semantic vector lookups via RedisVL — that cuts RAG latency from seconds to milliseconds and slashes API spend by up to 80%. With tenant isolation, TTL tiers, and the precision metrics that keep it honest.
Read post →
-
 AI
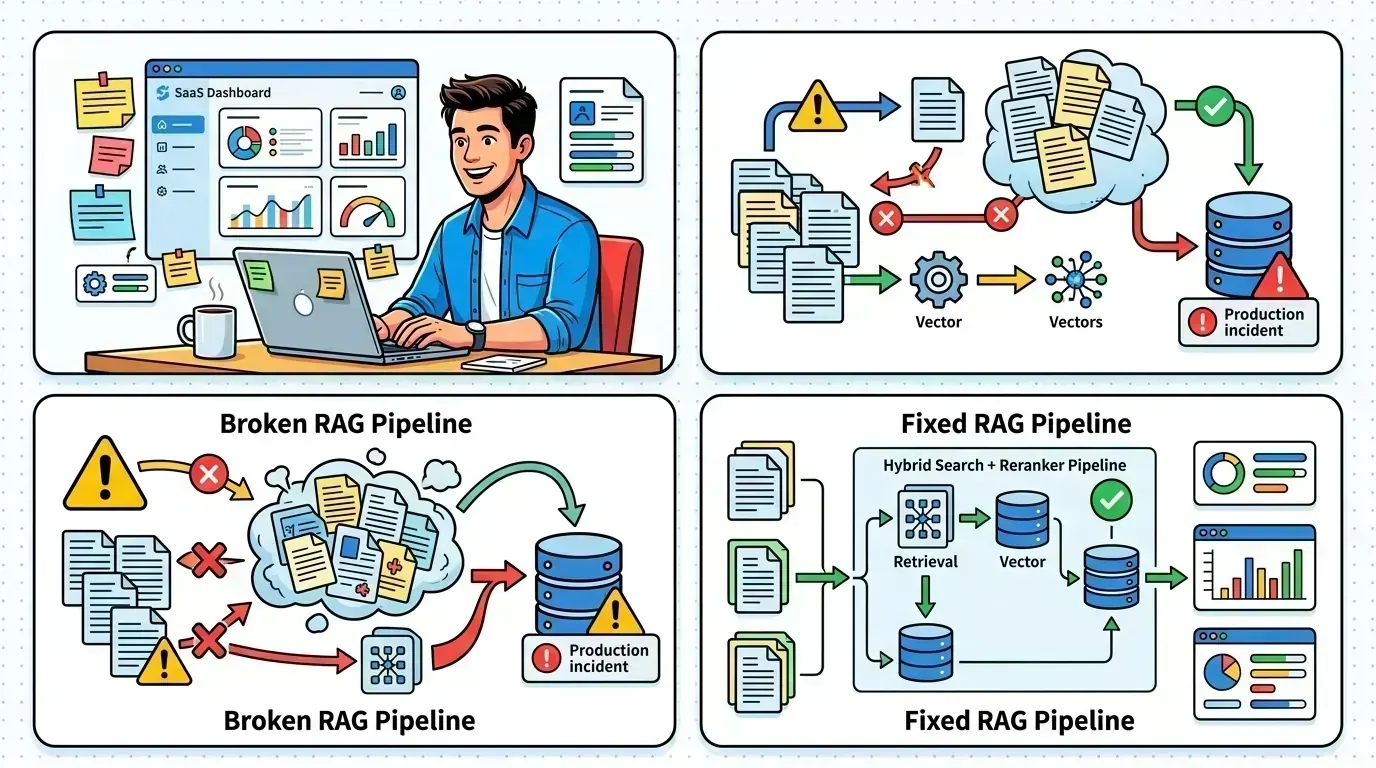
AIWhy your RAG implementation is failing in production (and how to fix it)
Vector-only retrieval is the silent killer of production RAG. Hybrid search with BM25, reciprocal rank fusion, smarter chunking, re-rankers, and an evaluation harness — the production checklist that turns a flaky demo into a reliable system.
Read post →