▸ Blog
Notes from the trenches.
Laravel internals, AI engineering with Claude + MCP, RAG pipelines, Shopify Plus, DevOps. Production lessons from shipped work — every post earns its slot. Featured = hand-picked or most recent.
▸ 28 posts · last updated
May 18, 2026
▸ New here? Start with these
Browse series- 01 Why your RAG implementation is failing in production (and how to fix it) AI
- 02 Laravel Octane: making PHP scream on high-traffic apps Laravel
- 03 Claude MCP: why I'm connecting my dev tools to LLMs for real-time context AI
- 04 The Coolify revolution: why I'm ditching expensive cloud providers for self-hosted SaaS DevOps
Browse by topic.
▸ Pick a lane · click a card to filter
Latest drop.
▸ Most recent · or pinned by hand

Why agentic commerce will change the way you build Shopify stores
AI agents don't browse — they query. The shift from human-centric Shopify themes to agent-ready infrastructure: Shopify Catalog, UCP, Agentic Storefronts, MCP servers, and why structured data is the new CSS.
Read post →
More posts.
▸ 9 of 27 · paginated below
-
 AI
AI7 mistakes you're making with your production RAG stack (and how to fix them)
Naive chunking, no reranker, embedding drift, latency blowups, vibe-checking — the seven structural mistakes that turn a slick RAG demo into a production nightmare, and the fixes that actually ship.
Read post →
-
 Architecture
ArchitectureScaling with RabbitMQ: why message brokers matter
Synchronous controllers are how monoliths die. RabbitMQ basics, exchanges and queues, the strangler pattern for going async, idempotent workers, and the Laravel queue setup I use to absorb 100k-row spikes without breaking the login page.
Read post →
-
 DevOps
DevOpsThe Coolify revolution: why I'm ditching expensive cloud providers for self-hosted SaaS
The 'cloud tax' kills SaaS margins before product-market fit. How Coolify — an open-source, self-hostable Heroku — plus ARM instances on Hetzner or Oracle's free tier cuts a $500/month AWS bill down to single digits, with zero vendor lock-in and a git-push deploy experience.
Read post →
-
 Laravel
LaravelLaravel Octane: making PHP scream on high-traffic apps
Standard PHP rebuilds the whole kitchen for every request. Laravel Octane boots once, stays warm in memory, and feeds requests through a worker pool — taking 50ms responses down to single digits. Swoole vs RoadRunner, worker-pool tuning, and surviving persistent state without memory leaks.
Read post →
-
 Shopify
ShopifyYour quick-start guide to Shopify UCP: do this before June 15
AI agents are the biggest spenders of 2026 — and they can't see your store without a UCP manifest. How the Universal Commerce Protocol works, why the /.well-known/ucp endpoint is the robots.txt of agentic commerce, and a pre-deadline checklist to make your Shopify store a first-class citizen in the AI economy.
Read post →
-
 AI
AIClaude MCP: why I'm connecting my dev tools to LLMs for real-time context
The Model Context Protocol is the USB port for LLMs. One MCP server, any MCP-aware host — killing the M×N integration tax. How the host/client/server architecture works, the servers I run daily, and why the sandbox model makes it safe enough to plug into production.
Read post →
-
 Architecture
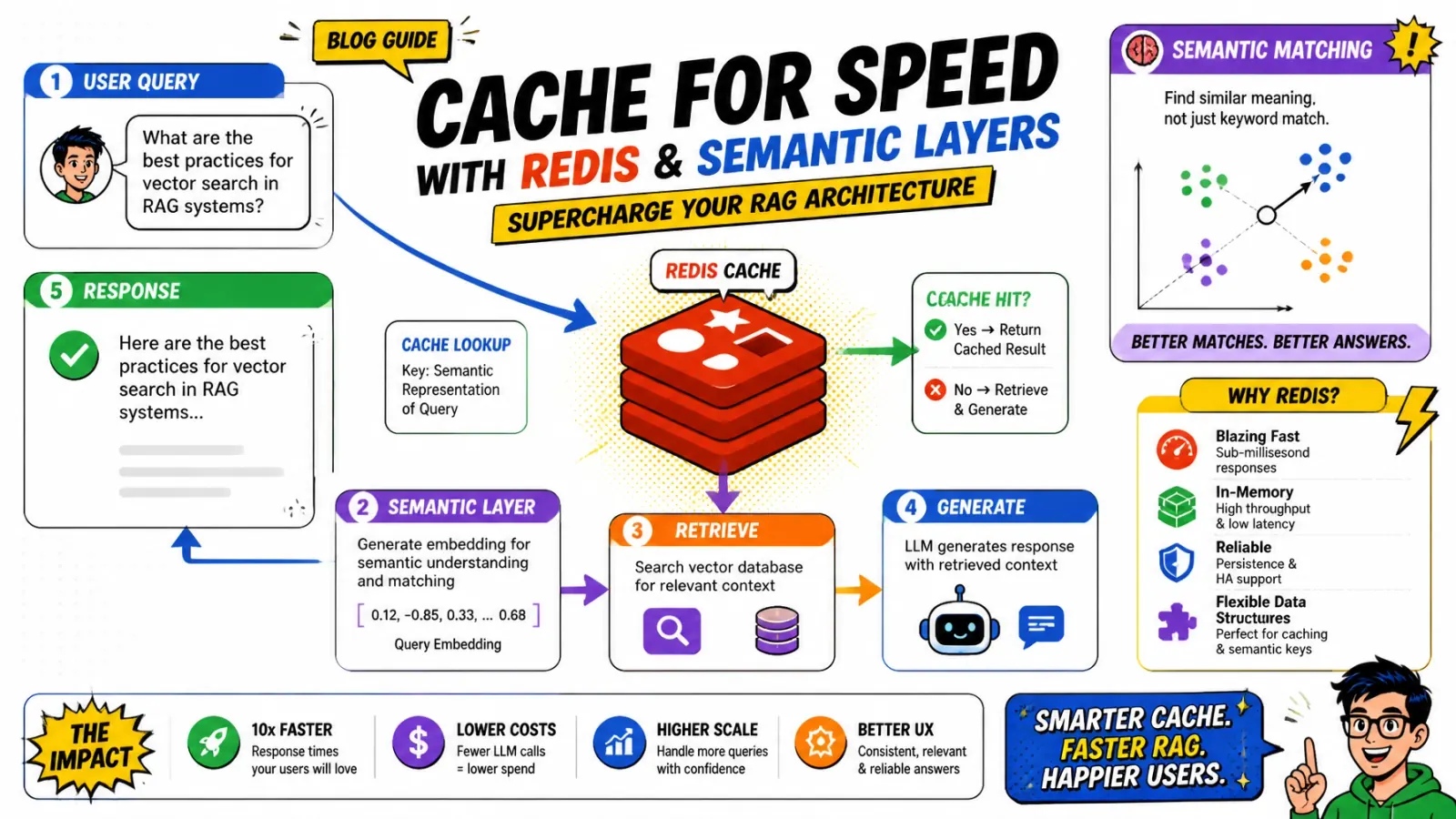
ArchitectureCaching for speed: Redis and semantic layers in RAG
Stop paying for the same LLM call twice. Two-tier caching — exact-match Redis keys plus semantic vector lookups via RedisVL — that cuts RAG latency from seconds to milliseconds and slashes API spend by up to 80%. With tenant isolation, TTL tiers, and the precision metrics that keep it honest.
Read post →
-
 Architecture
ArchitectureScaling on demand: smart auto-scaling for modern AI apps
CPU autoscaling is a lie for GPU workloads. Why queue depth, KV-cache pressure, and TTFT beat CPU as scaling triggers — KEDA-driven patterns, ARIMA forecasting, and composite metrics that scale your AI SaaS before users hit the spinner.
Read post →
-
 Architecture
ArchitectureGPU-aware load balancing: managing AI compute like a pro
Round-robin is a relic when LLM requests span 50 tokens to 50,000. Prefill vs decode disaggregation, KV-cache-aware routing, prefix matching, and the four metrics that matter — how to route AI traffic so your P99 stops bleeding.
Read post →
Tags.
▸ Search by specific tech