▸ Tag · #ai
Posts tagged #ai.
13 posts with this tag.
-
 Shopify
ShopifyWhy agentic commerce will change the way you build Shopify stores
AI agents don't browse — they query. The shift from human-centric Shopify themes to agent-ready infrastructure: Shopify Catalog, UCP, Agentic Storefronts, MCP servers, and why structured data is the new CSS.
Read post →
-
 AI
AI7 mistakes you're making with your production RAG stack (and how to fix them)
Naive chunking, no reranker, embedding drift, latency blowups, vibe-checking — the seven structural mistakes that turn a slick RAG demo into a production nightmare, and the fixes that actually ship.
Read post →
-
 Shopify
ShopifyYour quick-start guide to Shopify UCP: do this before June 15
AI agents are the biggest spenders of 2026 — and they can't see your store without a UCP manifest. How the Universal Commerce Protocol works, why the /.well-known/ucp endpoint is the robots.txt of agentic commerce, and a pre-deadline checklist to make your Shopify store a first-class citizen in the AI economy.
Read post →
-
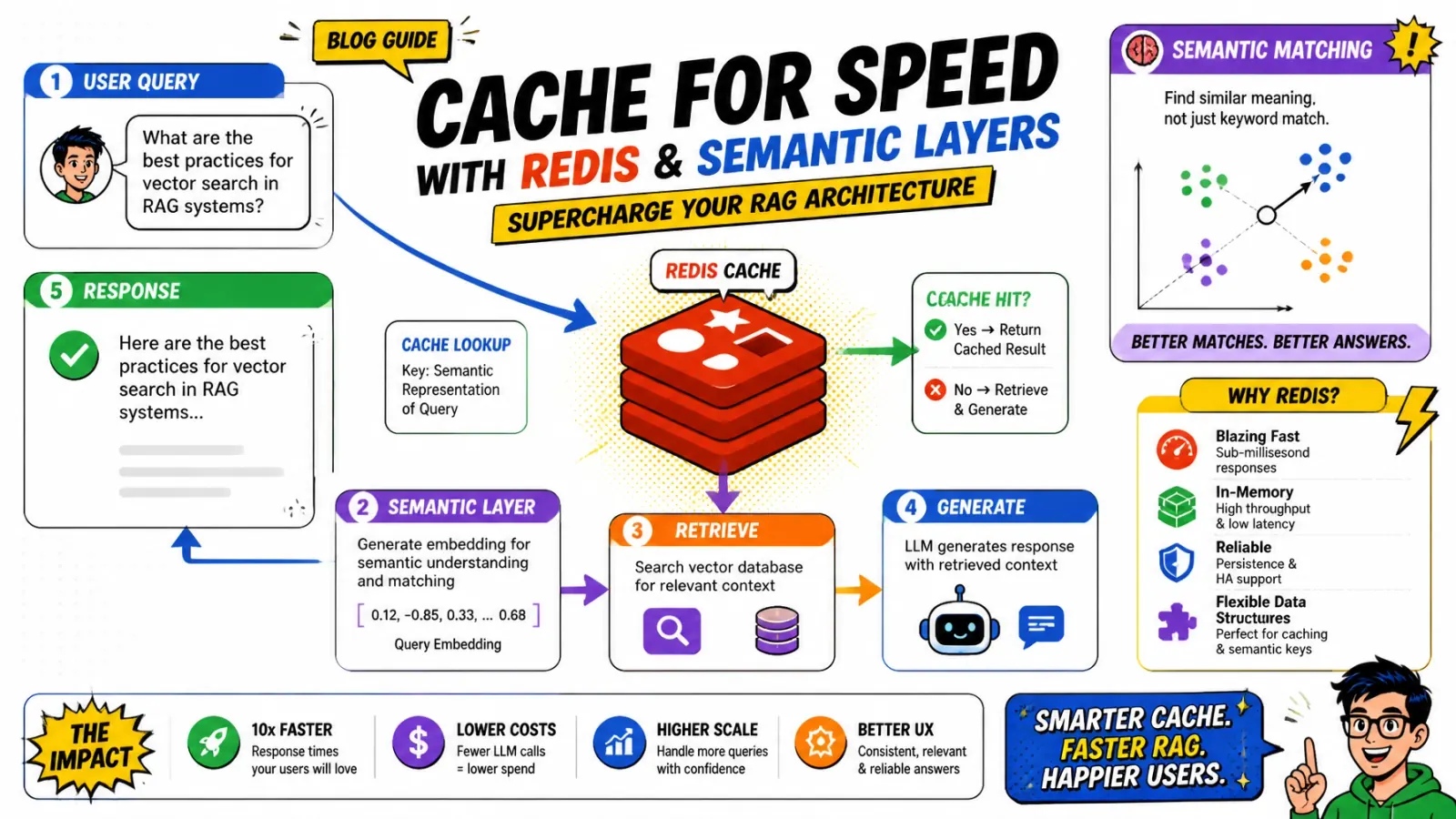 Architecture
ArchitectureCaching for speed: Redis and semantic layers in RAG
Stop paying for the same LLM call twice. Two-tier caching — exact-match Redis keys plus semantic vector lookups via RedisVL — that cuts RAG latency from seconds to milliseconds and slashes API spend by up to 80%. With tenant isolation, TTL tiers, and the precision metrics that keep it honest.
Read post →
-
 Architecture
ArchitectureScaling on demand: smart auto-scaling for modern AI apps
CPU autoscaling is a lie for GPU workloads. Why queue depth, KV-cache pressure, and TTFT beat CPU as scaling triggers — KEDA-driven patterns, ARIMA forecasting, and composite metrics that scale your AI SaaS before users hit the spinner.
Read post →
-
 Architecture
ArchitectureGPU-aware load balancing: managing AI compute like a pro
Round-robin is a relic when LLM requests span 50 tokens to 50,000. Prefill vs decode disaggregation, KV-cache-aware routing, prefix matching, and the four metrics that matter — how to route AI traffic so your P99 stops bleeding.
Read post →
-
 Architecture
ArchitectureCircuit breakers: preventing cascading failures in your vector DB
A slow vector DB kills SaaS faster than a dead one. The circuit-breaker pattern for AI infrastructure — closed/open/half-open states, fallback tiers, semantic caches, LLM-only mode, and Laravel-friendly wiring to keep production from melting under one bad dependency.
Read post →
-
 Architecture
ArchitectureMessage queues: handling the heavy lifting of document processing
Stop running embeddings inside the request-response cycle. A production-grade document ingestion pipeline — staged workers, exponential backoff, dead-letter quarantines, batched embeddings, and queue-depth autoscaling that keeps your AI app from melting under a 500-page PDF.
Read post →
-
 Architecture
ArchitectureRate limiting: protecting your AI wallet
One runaway agent loop = $5,000 OpenAI bill. Why request-per-second limits lie for LLM apps, how to architect hierarchical token-bucket limits across global / tenant / user layers, and adaptive throttling patterns that protect margins without breaking UX.
Read post →
-
 Architecture
ArchitectureAPI Gateway: the front door of your AI stack
Stop exposing LLM providers directly to the frontend. The gateway pattern for AI apps — JWT-scoped tenant isolation, model aliases, denial-of-wallet rate limiting, streaming-safe timeouts, and the wallet-saving guardrails every senior engineer needs.
Read post →
-
 AI
AIWhy your RAG implementation is failing in production (and how to fix it)
Vector-only retrieval is the silent killer of production RAG. Hybrid search with BM25, reciprocal rank fusion, smarter chunking, re-rankers, and an evaluation harness — the production checklist that turns a flaky demo into a reliable system.
Read post →
-
 Architecture
ArchitectureAI integration vs traditional development: which is better for your business in 2026?
Speed, control, or a hybrid path? When AI-assisted development pays off, when traditional engineering is non-negotiable, and the hybrid workflow I recommend most often to founders and tech leads.
Read post →
-
 AI
AIVibe coding: why your next project needs more than just logic
Logic is the skeleton. Vibe is the soul. Why taste, intent, and feel are the new senior-engineer superpowers in the Cursor + Claude era — and how to keep the codebase from turning into a ball of mud while you chase it.
Read post →