You built a beautiful RAG pipeline. It works perfectly on your machine with a few hundred vectors. Then you launch. Traffic spikes. Suddenly your managed vector database starts sweating. A single similarity search that used to take 50ms is now taking 5 seconds. Your web workers are all tied up waiting for responses that aren’t coming. The database isn’t technically down — but it is slow enough to kill your entire application. Your users see spinning loaders until the request finally times out. This is a classic cascading failure, and it is the fastest way to drain your “innovation budget” and your users’ patience.
The problem is that we often treat external APIs and databases as if they are always healthy. We write code that assumes the vector DB will return results. When it doesn’t, we wait. And while we wait, we hold onto memory and CPU cycles. The solution is an old-school electrical engineering concept applied to software: the circuit breaker.
In this guide I want to show you how to wrap your AI infrastructure in protective logic so a slow dependency doesn’t take your whole SaaS down with it.
Understanding the three states
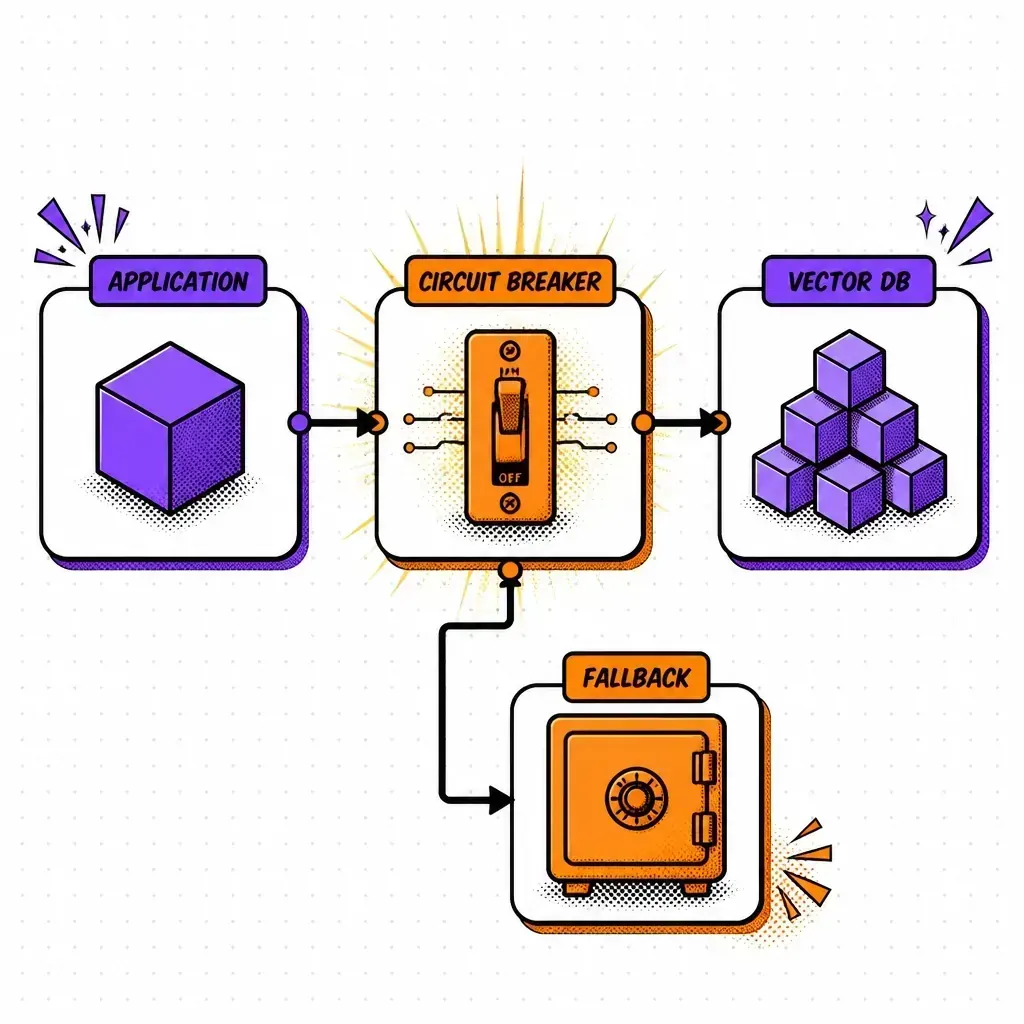
The circuit breaker pattern is a state machine that sits between your application code and your external service. It monitors every call you make. It has three specific states that dictate how it handles traffic.

Closed — the healthy state. In the closed state, the circuit is complete. Requests flow through to your vector database or LLM provider normally. The breaker is silently watching. It keeps a count of how many requests failed or took too long. As long as the failure rate stays below your threshold, it stays closed. This is the “everything is fine” mode.
Open — the fail-fast state. Once the failure threshold is hit — let’s say 50% of requests failed in the last 30 seconds — the breaker “trips” and moves to the open state. Now, every time your application tries to call the vector DB, the breaker immediately throws an error or returns a fallback response without even attempting the network call. This gives your database room to breathe and recover. It also ensures your application doesn’t waste time waiting on a service that is clearly struggling.
Half-open — the recovery test. After a cooldown period, the breaker moves to the half-open state. It allows a small number of “test” requests to pass through. If these test calls succeed, the breaker assumes the service is healthy again and moves back to the closed state. If they fail, it immediately goes back to open for another cooldown cycle. This is a controlled way to probe the system before fully re-engaging.
Why your RAG pipeline needs this
RAG pipelines are particularly vulnerable because they usually involve multiple high-latency network hops. You have to embed the query, search the vector DB, and then call the LLM. If any of these pieces fail or slow down, the whole experience breaks.
Most developers make the mistake of only handling hard errors like a 404 or a 500 status code. But in production, “slow” is often more dangerous than “down.” A slow vector DB creates a bottleneck that backs up your entire request queue. By the time you realize there is a problem, your server is out of memory because it is holding open thousands of connections.
If you have read my previous post on 7 RAG mistakes in production, you know that reliability is the difference between a demo and a product. The circuit breaker is your insurance policy against these types of outages.
Implementing fallback strategies
Tripping the breaker shouldn’t always mean showing an error message to the user. The best AI systems use fallbacks to maintain a level of service even when parts of the stack are failing.
Hot and cold tiers. You can think of your vector DB as your “hot” knowledge tier. If it fails, you should have a “cold” fallback. Maybe you fall back to a standard keyword search in your primary Postgres or MySQL database. The results might not be as contextually relevant as a vector search, but a “decent” answer is always better than a “timed out” error.
Cached responses. Another great strategy is semantic caching. If the circuit is open, you can check a Redis cache for similar queries that were answered recently. Even if you can’t generate a fresh answer, you might be able to serve a cached one. This keeps the user moving while your backend recovers.
LLM-only mode. If your retrieval step is what’s failing, you can still send the user’s prompt to the LLM with a note that external knowledge is currently unavailable. The LLM can then answer based on its general training data. It is a degraded experience, but it is still functional. Transparency here is key — tell the user that the “live” data isn’t available so they know to verify the response.
Building it in Laravel
Since I spend a lot of time in the Laravel ecosystem, I often use tools that make this easy to implement. You don’t need to write the state machine from scratch. Packages like spatie/resilience or even building a custom wrapper around the illuminate/http client can get the job done.
The goal is to wrap your API calls in a block that understands these states. Here is a simplified look at how that logic looks in practice.
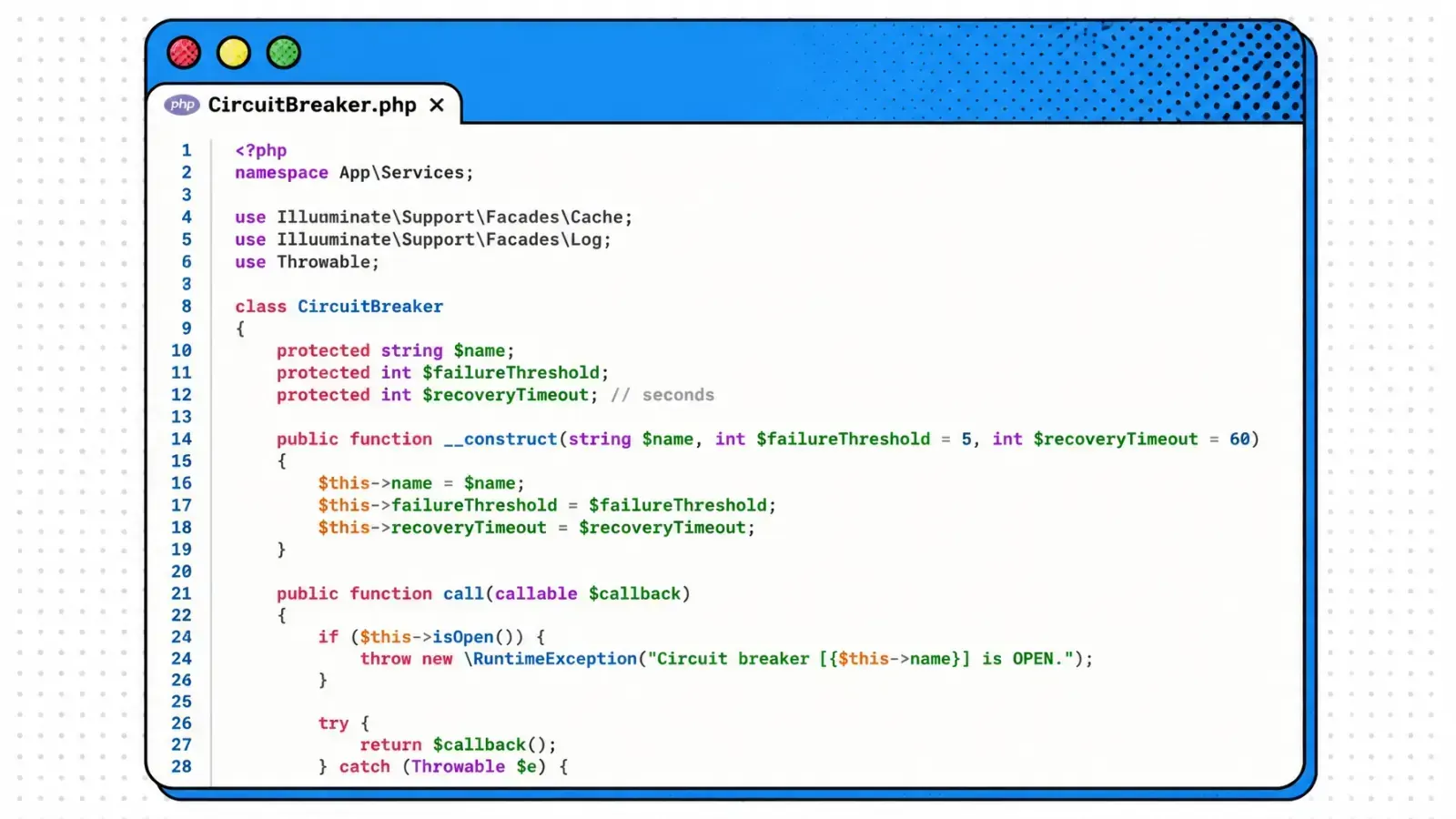
When you call your vector DB client, you wrap it in the breaker. If the call fails multiple times, the breaker trips. In the catch block, you handle the CircuitBreakerOpenException by returning your fallback data. This keeps your controllers clean and your architecture robust.
You can also integrate this with your SaaS hosting on Coolify to ensure that your containers don’t get killed by health checks just because an external API is slow. The breaker prevents the resource bloat that usually triggers those health-check failures.
Live telemetry and smart routing
Senior engineers don’t just set a circuit breaker and walk away. They monitor it. You need live telemetry to see how often your circuits are tripping. Tools like Prometheus or even simple logs piped to a dashboard can tell you a lot.
If you see that your primary vector DB in us-east-1 is constantly tripping but your secondary in eu-west-1 is healthy, you can implement smart routing. Your circuit breaker can act as a signal to your load balancer or your internal router to shift traffic to the healthy region.
This kind of event-driven architecture makes your system self-healing. It doesn’t wait for a human to wake up at 3am to fix a database. It detects the failure, trips the breaker, uses the fallback, and tries to recover automatically.
Practical steps to get started
If you are ready to harden your AI infrastructure, start here:
- Identify your weakest links — list every external call in your RAG pipeline. Usually it is the embedding API and the vector DB.
- Define your thresholds — how many slow requests are you willing to tolerate? Start with a 50% failure rate over 30 seconds and a 2-second timeout.
- Choose your fallbacks — decide what happens when the breaker is open. Do you show an error, use a cache, or switch to keyword search?
- Wrap your clients — use a library to wrap your HTTP or database calls. Don’t try to build the state machine logic yourself unless you have a very specific use case.
- Monitor the trips — set up an alert when a circuit stays open for more than a few minutes. This usually indicates a major provider outage that needs your attention.
The goal is to fail gracefully. Every system has issues, but the ones that survive are the ones that don’t let a small fire in a dependency burn down the whole house.
Have you ever had a slow dependency take down your entire application, or are you still relying on long timeouts and luck? Drop a note via contact — I love this conversation. 🤘