One runaway agent loop is all it takes to wake up to a $5,000 OpenAI bill.
If you’re building AI-powered SaaS or RAG systems, your biggest threat isn’t a server crash. It’s a “denial of wallet” attack. A buggy client, a malicious user, or even your own experimental agent can spam your API endpoints and burn through your tokens (and credits) in minutes.
Traditional web apps care about requests per second to keep the CPU from melting. In the world of LLMs, we care about tokens per minute to keep the bank account from draining. Standard rate limiting isn’t enough anymore. You need an architecture that understands cost, context, and the “noisy neighbor” problem before a single prompt even hits your vector DB.
Why requests per second (QPS) is a lie for AI
In a standard Laravel or Node app, a request is a request. Sure, some take longer than others, but they generally consume similar resources. In AI engineering, one request might be a 50-token greeting, while another is a 128,000-token context dump for a RAG pipeline.
If you only limit requests per second, a single user can stay within their “10 requests per minute” limit while still costing you 100× more than everyone else combined. This is where the noisy neighbor problem becomes a financial crisis.
You aren’t just protecting your infrastructure. You’re protecting your margins. To do this effectively, we have to move from counting “pings” to counting “value.”
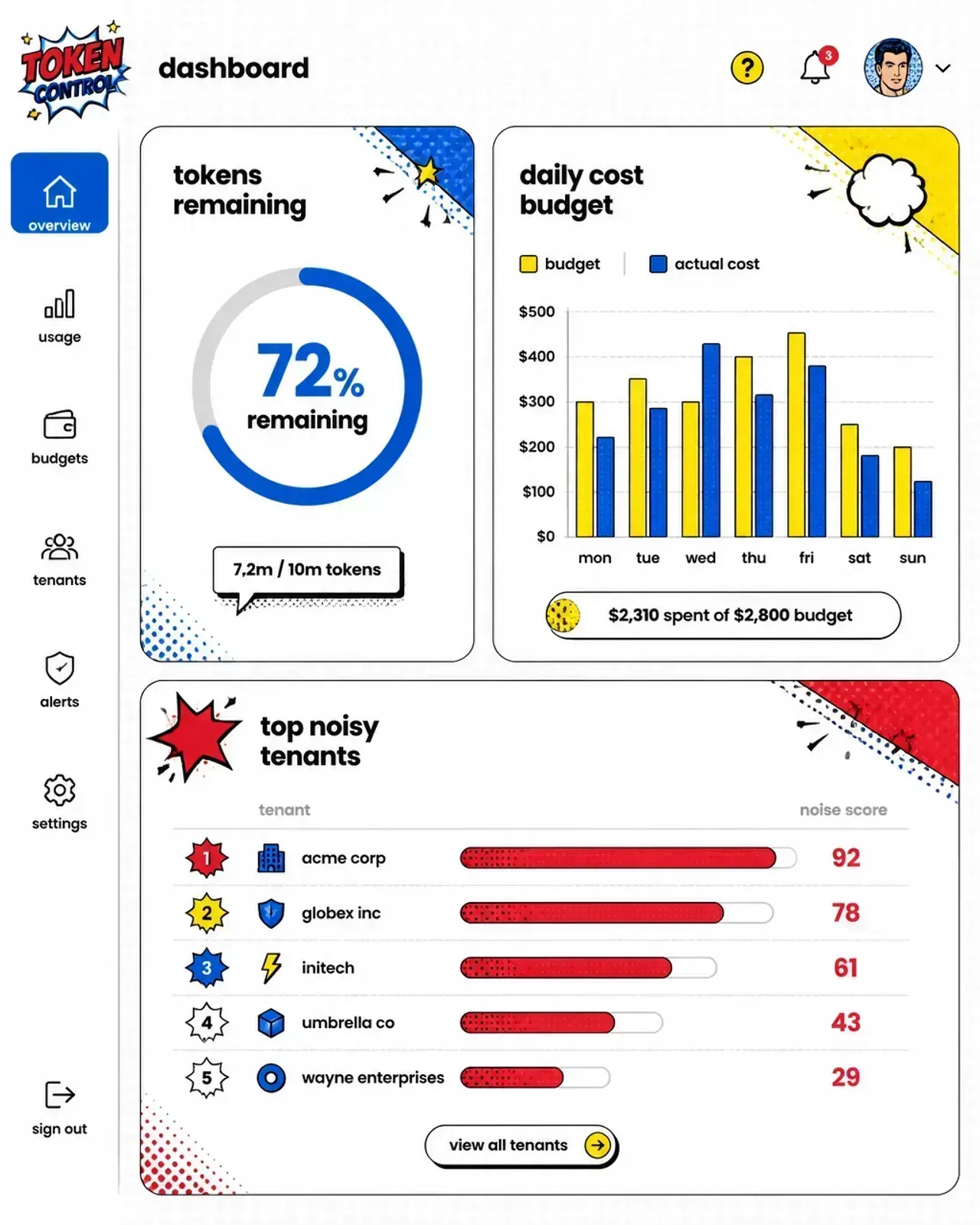
The anatomy of a denial of wallet (DoW) attack
A denial of wallet attack is the AI equivalent of a DDoS. The goal isn’t necessarily to take your site down. It’s to exhaust your API quotas or financial budget until your service stops functioning — or you’re forced to pay a massive bill.
I’ve seen this happen in three ways:
- The agentic loop — an autonomous agent gets stuck in a logic loop, calling your tool-use functions repeatedly without a “max steps” ceiling.
- The scrapers — malicious bots trying to exfiltrate your entire knowledge base by querying every possible permutation of your RAG system.
- The dev mistake — a frontend developer accidentally puts an LLM-powered “autocomplete” on a search bar that triggers on every keystroke.
Without token-aware rate limiting, your provider (like OpenAI or Anthropic) will eventually hit you with a 429 error. But by that time, the damage to your wallet is already done.
Solving the noisy neighbor with hierarchical limits
To solve this, I implement a three-layer rate limiting strategy at the API gateway level. This ensures that even if one tenant goes rogue, the rest of the platform stays healthy.
1. The global provider layer
This is your final line of defense. If your OpenAI quota is 500,000 tokens per minute (TPM), set your internal global limit to 450,000. This leaves a safety buffer and prevents you from actually hitting the provider’s hard ceiling, which can sometimes lead to temporary account bans or throttled priority.
2. The tenant layer
Every customer gets their own bucket. I usually tie this to their subscription tier. A “Pro” user might get 50,000 TPM, while a “Free” user is capped at 2,000. This ensures no single company can eat up your entire global quota.
3. The user/session layer
Inside a single tenant, you still need limits. You don’t want one single employee at a customer’s company hogging all the tokens allocated to that entire organization. I set these at about 20% of the total tenant capacity.
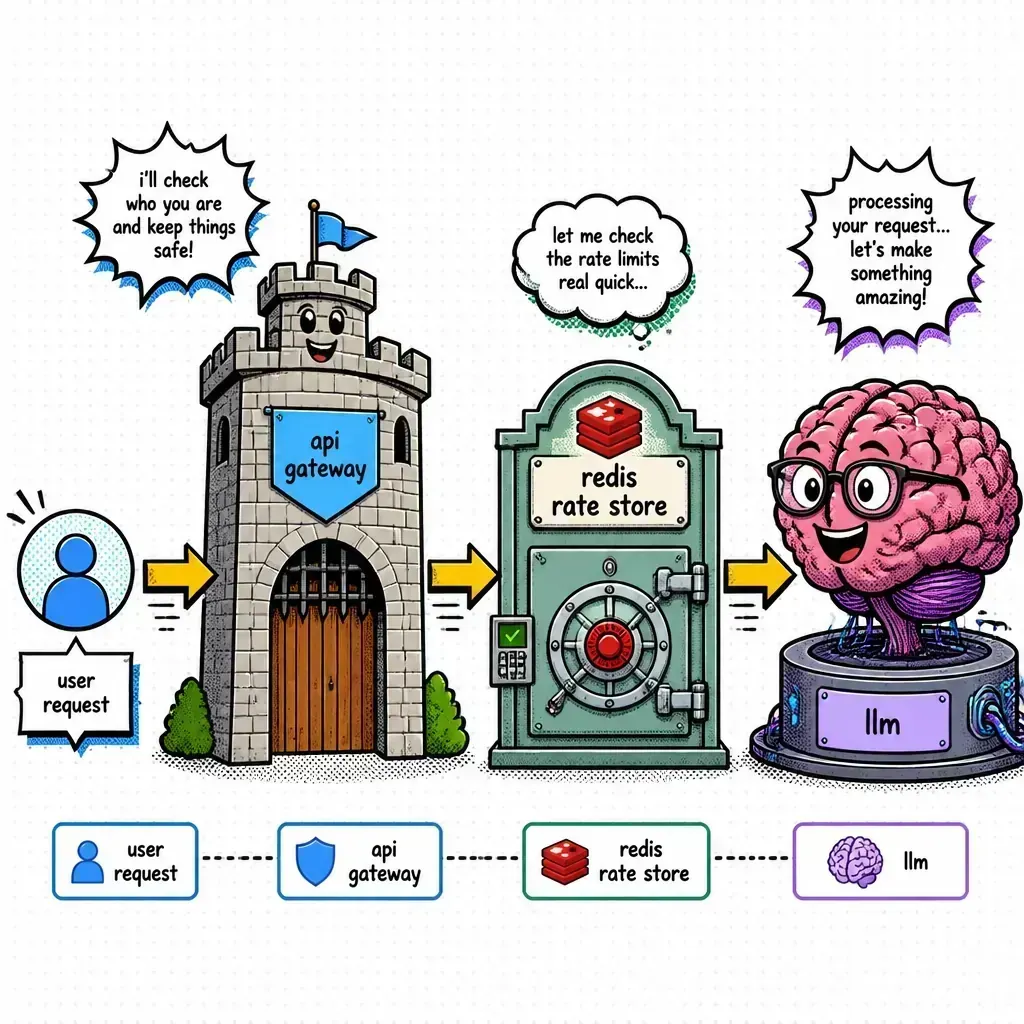
Implementation: the token bucket algorithm
For most of my builds, I use a “token bucket” or “leaky bucket” algorithm backed by Redis. It’s the gold standard for handling bursty traffic while maintaining a steady flow.
Here is the logic: each user has a “bucket” of tokens. Every time they send a prompt, we estimate the total cost (input tokens + expected max_tokens). If the bucket has enough, they proceed and the tokens are deducted. The bucket refills at a constant rate over time.
If you’re modernizing your stack or building a SaaS on the LEMP stack, you can implement this efficiently in Laravel using middleware and a fast storage layer like Redis.
// A simplified token-bucket check in Laravel middleware
public function handle($request, Closure $next)
{
$tenantId = $request->user()->tenant_id;
$estimatedTokens = $this->tokenizer->estimate($request->input('prompt'));
if (!$this->limiter->consume("tenant:{$tenantId}:tokens", $estimatedTokens)) {
return response()->json(['error' => 'token budget exceeded'], 429);
}
return $next($request);
}
Token-budget routing and adaptive throttling
What happens when a user hits their limit? Most devs just throw a 429 error. But as a senior engineer, I prefer a more graceful degradation. We call this adaptive throttling.
Instead of a hard “no,” you can:
- Degrade the model — switch the request from GPT-4o to a cheaper, faster model like GPT-4o-mini.
- Truncate the context — if the user is over budget, strip out some of the retrieved RAG documents to lower the input token count.
- Queue the request — for non-interactive tasks (like background summarization), move the request to a message queue and process it when the token bucket refills.
This keeps the user experience intact while protecting your margins. It’s about being smart, not just being a gatekeeper.
The RAG context: limiting the “hidden” calls
In a RAG (retrieval-augmented generation) system, one user query often triggers multiple backend actions:
- One embedding call for the query.
- One search query to the vector database.
- One (or more) LLM calls for the final answer.
If you only rate limit the final LLM call, your vector database might still get hammered by search queries. You need to treat the entire “RAG flow” as a single unit of work with its own combined budget. I cover some of these common RAG production mistakes frequently, but rate limiting the “flow” is often the most overlooked fix.
Practical steps to protect your system today
If you’re launching an AI feature this week, do these three things:
- Set a hard daily spend cap — most API providers let you set a maximum dollar amount per month. Set it. It’s your parachute.
- Enforce
max_tokens— never let a user request an uncapped response. Always set a sane default formax_tokensin every API call. - Implement per-request timeout — if an LLM call takes longer than 30 seconds, kill it. Slow calls are often the symptom of a system that is about to spiral out of control.
Rate limiting isn’t just a “security” feature. In the AI era, it’s a core part of your business model. You can’t scale a product that allows a single user to run up a thousand-dollar bill in their first hour.
Build for fairness. Build for cost. Build for the “noisy neighbor.”
Have you ever seen a “denial of wallet” happen in the wild, or are you still running on a wing and a prayer with global provider limits? Drop a note via contact — I love this conversation. 🤘